期待していた成果が出なかったときや、SNSの「いいね!」が予想より少なかったとき。
逆に、思いがけず評価されたときは、いつも以上に嬉しく感じませんか?
実はこうした感情の動きには、報酬予測誤差という脳の仕組みが関わっています。
この記事では、報酬予測誤差の基本から、ドーパミンとの関係や学習の仕組み、さらに恋愛・SNS・習慣など身近な例までわかりやすく解説します。
報酬予測誤差とは?基本的な意味と仕組み
「予測」と「現実の差」が学習を生む
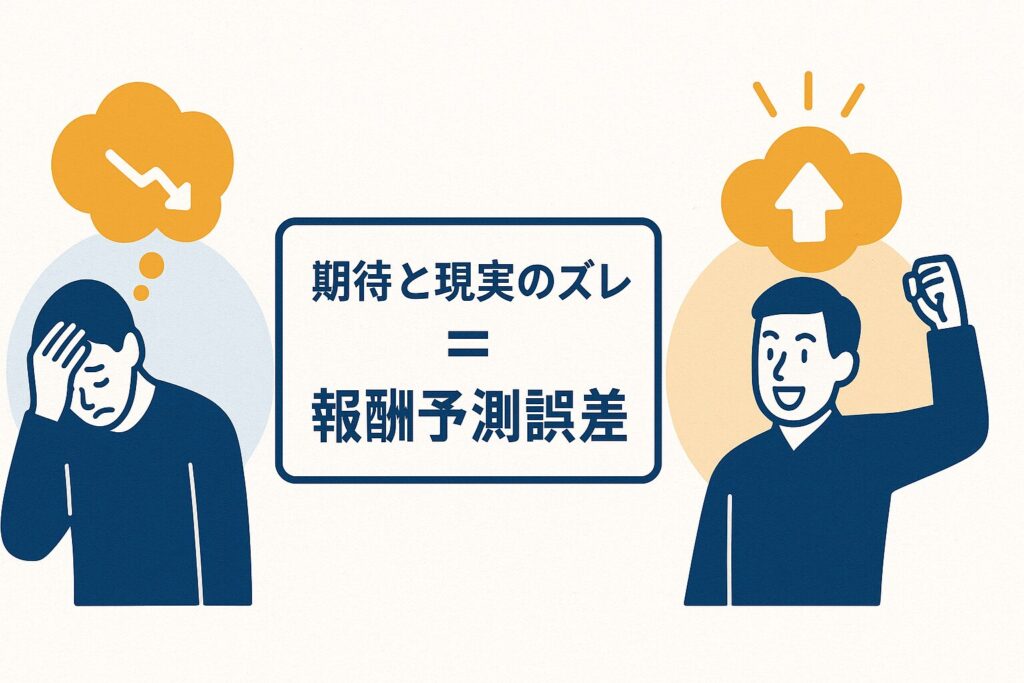
報酬予測誤差(Reward Prediction Error)とは、簡単に言えば「期待したご褒美」と「実際に得られたご褒美」の差」のことです。
人間や動物は、ある行動をすると「これくらいの報酬がもらえるだろう」と心の中で予測しています。
- 予想以上に良い結果が返ってきた → プラスの誤差(嬉しい驚き)
- 予想通りの結果だった → 誤差なし(新しい学びは少ない)
- 予想より悪い結果だった → マイナスの誤差(がっかり感)
この「誤差」があることで、
脳は「これは良かったのか、ダメだったのか」を判断します。
そして、
「良かったことは続ける」「ダメだったことはやめる」
という形で、次の行動が変わっていきます。
つまり、報酬予測誤差は
行動を繰り返すかやめるかを決める仕組みとも言えます。
報酬予測誤差とドーパミンの関係
報酬予測誤差の裏側では、ドーパミンという脳内物質が大きな役割を担っています。
ドーパミンは「快楽物質」と呼ばれることが多いですが、
実際には 予想と結果のズレ(報酬予測誤差)を脳に伝え、行動や学習を調整する働きがあります。
- 予想外のご褒美 → ドーパミンが増える(強い喜び)
- 予想通りのご褒美 → ドーパミンは変化しない(学習も進まない)
- 期待していたのにご褒美なし → ドーパミンが減る(落胆し、行動を見直す)
この仕組みがあるからこそ、人は成功や失敗から学び、次の行動を調整できるのです。
日常生活に例えるとわかりやすいシーン(サプライズ・がっかり感など)
報酬予測誤差は専門的な言葉ですが、私たちの日常にたくさん存在しています。
- サプライズプレゼント:まったく予想していなかった誕生日プレゼントをもらうと、期待を大きく超えるため強い喜びを感じます。
- レストランでの注文:想像以上においしい料理に出会えばプラスの誤差、逆に期待外れならマイナスの誤差。
- スポーツ観戦:応援していたチームが予想外に勝利すると、通常以上に興奮するのも報酬予測誤差の効果です。
このように「予想と現実の差」が感情を大きく動かし、その体験が次の行動や記憶に影響していきます。
報酬予測誤差の別名・英語表記(リワードプレディクションエラー)
報酬予測誤差は英語で Reward Prediction Error(リワード・プレディクション・エラー) と呼ばれます。
海外の研究や論文では、この英語表記や略称の RPE が使われることが多いです。
また、似たような表現として以下の言い方もあります。
- 予測報酬誤差(日本語の言い換え)
- 期待誤差(やや一般的な表現)
- 予測誤差(Prediction Error)(より広い概念)
ただし、これらには少しニュアンスの違いがあります。
- 報酬予測誤差
→「ご褒美(報酬)」に限定した誤差 - 予測誤差
→音や光なども含めた、すべての予測ズレ
つまり、報酬予測誤差は「予測誤差の中でも、特に報酬に関するもの」と理解すると分かりやすいです。
報酬予測誤差の理論モデル|心理学・AIで使われる考え方
Rescorla-Wagnerモデル(古典的条件づけの学習理論)
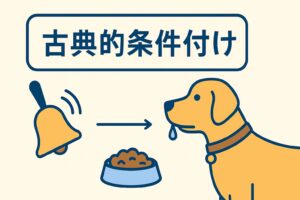
Rescorla-Wagnerモデル(レズコーラ=ワグナー理論)とは、動物の古典的条件づけを説明する心理学モデルです。
犬にベルの音を聞かせてからエサを与える実験をイメージするとわかりやすいでしょう。
- 最初はベルの音とエサは無関係。
- 何度も「ベル → エサ」が続くと、「ベル=エサが来る」と学習する。
- しかしエサが来なかったときには「予測と現実のズレ」が生じ、そこで学習が修正される。
つまり、このモデルは 報酬予測誤差を使って学習が進む仕組みを数式化したもの で、心理学における学習理論の基盤となっています。
数式のイメージ
学習の変化量をΔV、報酬の大きさをλ、予測した報酬をVとすると、
モデルは次のように表されます:
ΔV = αβ (λ − V)
この式は一見難しそうですが、言っていることはシンプルです。
「予想と結果のズレが大きいほど、人は強く学ぶ」という意味です。
つまり、
学習の変化量 = 学習の強さ × 予想と結果のズレ
例えば
- 思ったより良い結果だった
→ 「これはいい!」と強く記憶する
- 思ったより悪い結果だった
→ 「これはダメだ」と修正する
- 予想通りだった
→ 特に変化なし(学びは少ない)
ズレが大きいほど、行動は大きく変わります。
この「ズレ」が
λ − V(報酬予測誤差)
そして、そのズレにどれくらい影響を受けるかが
αβ(学習の強さ) です。
αβは「どれくらい学びやすいか(影響の受けやすさ)」を表しています。
こういう意味があります。
- α(アルファ)
→ どれくらいその刺激に注目しているか - β(ベータ)
→ どれくらい学びやすい状態か
現実の学習には例外もある
Rescorla-Wagnerモデルは学習の基本的な仕組みを説明する理論ですが、
実際の人間の学習はもっと複雑です。
例えば、
「気づいているかどうか」や「すでに知っていること」などによって、
同じズレがあっても学習のされ方が変わることがあります。
そのため、このモデルだけでは説明しきれないケースも存在します。
この理論のポイント
- 学習は「誤差ゼロ」を目指して進む(ズレがなくなるまで調整)
- 報酬予測誤差が学習の原動力
- 一度予測が正確になると、刺激だけでは新しい学びは起こりにくくなる
- Rescorla-Wagnerモデルは基本を説明する理論だが、現実の学習には例外もある
強化学習とTemporal Difference学習(AIへの応用)
Temporal Difference学習(TD学習/時間差分学習)とは、AIの強化学習アルゴリズムで使われる方法です。
これは人間や動物の報酬予測誤差の仕組みを参考に作られています。
- 「行動を選ぶ → 結果を得る → 予測とのズレを修正」
- この繰り返しで、AIは最適な行動を学習していく。
例えば、囲碁AI「AlphaGo」が人間のプロ棋士に勝てるようになったのも、このTD学習を応用した強化学習の力によるものです。
人間の脳とAIの学習アルゴリズムが、同じ「誤差修正の原理」で動いているというのはとても興味深い点です。
名前の意味(なぜ“時間差分”?)
「Temporal Difference」とは 時間的な差分 という意味です。
つまり、ある状態での予測(V)と、その後に得られる報酬+次の状態での予測(r+V’)との差を使って学習します。
ざっくり数式で表すと:
TD誤差 = r + γV’ − V
このTD誤差が「報酬予測誤差」にあたり、それを使って学習を進めます。
- r = 実際の報酬
- V = 現在の予測値
- V’ = 次の状態での予測値
- γ(ガンマ)=割引率(0〜1の値)⇒ 未来の報酬をどれくらい現在の価値として扱うか)
ここで γ があることで、「未来の報酬は遠くなるほど価値が薄れる」という調整ができます。
報酬予測誤差とプロスペクト理論(行動経済学との関連)
行動経済学のプロスペクト理論(カーネマンとトヴェルスキーが提唱)とも報酬予測誤差は関係しています。
この理論は「人は利益よりも損失に敏感」という特徴を説明します。
- 予想以上の利益 → 強い喜び(プラスの予測誤差)
- 予想外の損失 → それ以上に強い不快感(マイナスの予測誤差)
つまり、経済行動においても「期待と結果の差」が感情と意思決定を大きく左右しているのです。

脳科学が解明した報酬予測誤差|ドーパミンの役割
シュルツのサル実験(1997年)とドーパミン神経
報酬予測誤差の理解を一気に深めたのが、ウォルフラム・シュルツによるサルの実験(1997年)です。
彼はサルの脳内でドーパミン神経の活動を測定しました。
その結果:
- 予想外のご褒美(バナナジュースなど)が与えられると、ドーパミンの活動が一気に増加。
- ご褒美が予測通りに出てきた場合、ドーパミンの反応はほとんど変化しない。
- 予想していたのにご褒美が出ない場合、ドーパミン活動が低下。
この実験は、ドーパミンが「快感そのもの」だけではなく、予測と現実のズレ(誤差)を脳に伝えるシグナルとして働くことを示しました。
人間の脳で見られる活動領域(線条体・前頭前野)
その後の脳科学研究(fMRIなど)では、人間でも同じような仕組みがあることが分かっています。
- 線条体:報酬や学習に関わる領域で、ドーパミンによる報酬予測誤差の信号を受け取り、活動が変化する。
- 前頭前野:意思決定や将来の予測に関与し、その情報をもとに「次の行動をどうするか」を判断する。
つまり「期待 → 結果 → 誤差 → 学習」の流れは、動物だけでなく人間の脳でも共通して働いています。
ドーパミンは「快感」だけでなく「予測のズレ」を伝える
一般的には「ドーパミン=快楽物質」と思われがちですが、
ドーパミンはそれだけでなく、「どれくらい予想と違ったか」を知らせる役割も持っています。
- 予想外の喜び → ドーパミン急増(もっとこの行動を繰り返そう!)
- 期待が外れる → ドーパミン減少(この行動は修正しよう…)
このシステムこそが、人が失敗から学んだり、新しいことに挑戦して適応したりできる理由の一つなのです。
報酬予測誤差と強化スケジュールの関係
強化スケジュールとは?(連続強化と部分強化の違い)
強化スケジュールとは、「報酬(ご褒美)をどのタイミングで与えるか」というルールのことです。
心理学では大きく2種類に分けられます。
- 連続強化:行動するたびに必ず報酬を与える(例:ボタンを押すと毎回お菓子が出る)。
- 部分強化:ときどき報酬を与える(例:ボタンを押しても、たまにしかお菓子が出ない)。
実は、部分強化の方が学習した行動は消えにくいことがわかっています。
なぜなら「次こそはもらえるかも」という予測と現実のズレ(報酬予測誤差)が繰り返されるからです。
部分強化が「やめられない行動」を生みやすい理由
連続強化の場合、報酬がなくなればすぐに「もう意味がない」と気づきます。
しかし部分強化では「今回もらえなかったけど、次は出るかもしれない」と考え、行動が続きやすくなります。
この仕組みによって、報酬予測誤差が何度も繰り返され、脳が強い学習をしてしまうのです。
そのため「やめられない習慣」や「依存行動」の背景には、部分強化が関わっているケースが多いとされます。
スロットマシンやガチャに見る「変動比率スケジュール」
もっとも強力に人を惹きつけるのが、変動比率スケジュールと呼ばれる方式です。
- スロットマシンやスマホゲームのガチャは、何回に1回報酬が出るかがランダム。
- 「次は当たるかも」という予測と「外れた」という現実の差が、常に脳を刺激する。
- 予想外に当たりが出たときの「サプライズ」が強烈な快感となり、繰り返しを促す。
これは報酬予測誤差を最大限に利用した仕組みであり、ギャンブル依存や課金中毒の心理的背景として有名です。
予測誤差を最大化する仕組みとしての強化スケジュール
強化スケジュールは単に「ご褒美を与えるルール」ではなく、報酬予測誤差を操作する仕組みだと言えます。
- 報酬のタイミングをランダムにする → 誤差が増える → 学習が強化される。
- 予測が外れた体験が続くほど、「次こそは」という期待が高まり、行動が維持されやすい。
このように、強化スケジュールは「報酬予測誤差の大きさ」をコントロールする装置のようなもので、人間の行動形成に大きな影響を与えています。

報酬予測誤差の具体例|私たちの行動との関係
ギャンブルやくじ引きにハマる心理
パチンコ・スロット・宝くじなどのギャンブルは、典型的に報酬予測誤差を利用した仕組みです。
「当たるかもしれない」という期待と、「外れた」という現実の差が脳を強く刺激します。
- 当たり → 予想外の喜び(プラスの予測誤差)
- 外れ → がっかり感(マイナスの予測誤差)
- 何度も繰り返すことで「次こそは」という期待が強まり、中毒的になりやすい
この仕組みは先ほど説明した変動比率スケジュールともつながっており、「やめられない行動」をつくりやすい背景になっています。
恋愛や人間関係での「期待と現実のギャップ」
報酬予測誤差は、人間関係や恋愛にも表れます。
例えば:
- 好きな人から返信が早く来た → 予想以上で嬉しい(プラスの誤差)
- 返信が遅かった、または来なかった → 期待が外れて落ち込む(マイナスの誤差)
こうした「期待と現実のギャップ」が感情を大きく揺さぶり、相手との関係性を深く記憶に刻みます。
時にはこのギャップが、執着や別れられない恋を生む心理的背景になることもあります。
SNSや承認欲求と「いいね!」中毒
SNSの「いいね!」やフォロワー数も報酬予測誤差と関係しています。
- 投稿に思った以上の「いいね!」がつく → 強い快感(プラスの誤差)
- 期待より少ない → がっかりして不安になる(マイナスの誤差)
- 予想が外れるたびにドーパミンが動き、スマホを何度もチェックしてしまう
この仕組みがあるため、SNSは一種の「報酬マシン」となり、承認欲求を強化し続けるのです。
マーケティング・習慣化での応用例
マーケティングでの「期待を超えるサービス」
ビジネスの現場では、顧客の期待と実際の体験の差が満足度を大きく左右します。
これこそが報酬予測誤差の考え方です。
- 期待以上のサービス → プラスの予測誤差 → 「また利用したい」と思う
- 期待通り → 誤差なし → 可もなく不可もなく
- 期待以下 → マイナスの予測誤差 → 不満やクレームにつながる
Appleや高級ブランドは、デザインや体験を通じて「予想以上の価値」を与え、多くの顧客に「選んで正解だった」と思わせています。
つまり、マーケティング戦略のカギは プラスの予測誤差を意図的に生み出すことなのです。
習慣化・行動改善への応用(モチベーション設計)
報酬予測誤差は、習慣化やモチベーション設計にもそのまま応用できます。
ポイントは「予測と結果のズレをどう作るか」です。
人は、毎回同じ結果だと慣れてしまい、やる気が下がります。
一方で、少しでも「予想外の変化」があると、脳が刺激されて行動が続きやすくなります。
例えば
- 毎日同じ作業だけをする → 飽きる(誤差ゼロ)
- たまに成果が出る・変化がある → 続けやすい(誤差あり)
この仕組みを意図的に使うと、行動をコントロールできます。
具体的な活用方法
- 小さなご褒美をランダムにする
→ 毎回ではなく「ときどき達成感や報酬を得る」ことで継続しやすくなる
- 成果の見える化をする
→ 予想より成長していると気づくと、プラスの誤差が生まれる
- 難易度を少しずつ上げる
→予想を少し超える成功体験が増え、モチベーションが維持される
逆にやる気が下がるパターン
- ずっと同じことの繰り返し
- 成果が見えない
- 期待と結果が完全に一致している
これらはすべて「報酬予測誤差が小さい状態」です。
報酬予測誤差とマンネリの関係

マンネリとは?心理学的に見た“予測どおり”の状態
「マンネリ」とは、物事が繰り返されるうちに新鮮さや刺激がなくなり、感情が動かなくなる状態を指します。
心理学的に見ると、これは報酬予測誤差がゼロに近づいた状態です。
- 最初は「どんな結果になるんだろう?」という驚きや喜びがある
- 予想と結果のズレが脳を刺激してドーパミンが出る
- しかし繰り返すうちに「結果が読める」ようになり、誤差が小さくなる
結果、驚きや期待が薄れ、感情の揺れが少ない=マンネリ につながります。
なぜ新鮮さがなくなると脳は刺激を感じなくなるのか
私たちの脳は、予想外の報酬があったときにドーパミンを活発に放出します。
しかし、毎回同じ結果が返ってくると、脳は「もう知ってる」と判断し、ドーパミン反応が弱まるのです。
- 最初のデートでのサプライズ → 強い喜び
- 何度も繰り返すうちに予想通りに → 感情が動かない
このように、報酬予測誤差の減少がマンネリの正体ともいえます。
マンネリを打破するためにできる工夫
マンネリを避けるには、意識的に「予測誤差」を作り出すことがポイントです。
ちょっとしたサプライズや新しい体験を取り入れると、脳が再び刺激を受けて活性化します。
- 恋愛:いつもと違うデートプランを提案する
- 仕事:新しいやり方や学びを取り入れる
- 習慣:ルーティンに小さな変化を加える
こうした工夫で「予測と結果のズレ」を意図的に生み出すことで、ドーパミン反応が戻り、飽きにくくなるのです。
まとめ|報酬予測誤差を理解すると行動の見え方が変わる
「驚き」と「ズレ」が学びの原動力になる
ここまで見てきたように、報酬予測誤差とは「期待と現実の差」を意味します。
人はその差があるからこそ学び、修正し、成長していきます。
- 予想以上の成果 → 喜びが強まり、行動が強化される
- 期待通り → 新しい学びは少ない
- 期待外れ → 落胆もするが、次の工夫につながる
つまり、私たちの行動や感情は「驚き」や「ズレ」によって磨かれていくのです。
脳科学から日常生活・ビジネスまで応用できる
報酬予測誤差は、単なる心理学の概念にとどまりません。
- 脳科学:ドーパミン神経が「誤差」をシグナルして学習を調整
- 心理学・AI:Rescorla-WagnerモデルやTD学習で数式化され、AIの学習にも応用
- 日常生活:恋愛・SNS・ギャンブルなど、感情の動きに直結
- ビジネス:期待を超える体験を提供することで、顧客満足やリピート率を高める
報酬予測誤差を理解すると、「なぜ自分はこんな行動を取るのか」「なぜあの商品やサービスに惹かれるのか」といった日常の行動が、これまでよりもクリアに見えてきます。

