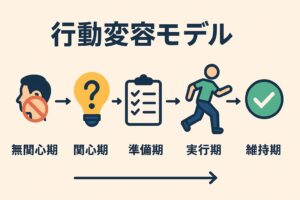
「行動を変えたいのに、続かない…」「やる気はあるのに三日坊主…」「叱っても、ほめても、うまくいかない…」
そんな経験はありませんか?
実は、人の行動は“意志”ではなく“設計”で変わります。
心理学でいうシェイピング(行動形成)とは、理想の行動を一気に変えようとせず、小さな成功を積み重ねて変えていく方法です。
この記事では、
- シェイピングの基本原理とスキナーの理論
- 習慣化・教育・マネジメントなどへの応用例
- 「叱るよりほめる」ではなく“設計する”という視点
をわかりやすく解説します。
「やる気に頼らず行動を続ける」ための科学的アプローチを知りたい方は、ぜひ最後まで読んでくださいね。
シェイピング法とは?意味と心理学的な基本原理をわかりやすく解説

シェイピング法の定義|行動を段階的に形成する心理学的手法
シェイピング(Shaping)とは、心理学で使われる専門用語で、
「理想の行動を一度に教えるのではなく、少しずつ段階的に近づけていく」という学習の方法です。
たとえば、子どもに「片づけをする習慣」をつけたい場合、
最初から「部屋を全部きれいにしなさい」と言ってもうまくいきません。
そこで、
- まずは“おもちゃを1つ片づけた”段階でほめる
- 次に“棚に戻す”ことをできたらさらにほめる
- 最終的に“自分から片づけを始めた”ら強く強化する
このように小さな成功を強化(ほめる・認める)していくことで、最終的な理想行動へ導くのがシェイピングの基本です。
つまりシェイピングとは、
「結果を急がず、段階的に行動を育てていく心理学的トレーニング法」
といえます。
スキナーが発見した「行動を育てる」学習理論
この考え方を体系化したのが、心理学者B.F.スキナー(Burrhus Frederic Skinner)です。
彼は「オペラント条件づけ理論」を提唱し、
「行動はその後に続く結果(報酬や罰)によって変化する」と説明しました。
このように、結果によって行動が変化する仕組みを「強化」といいます。
「少しずつ褒める」だけではない、シェイピングの本当の目的
シェイピングというと、「とにかく褒めればいい」というイメージを持たれがちですが、
本質は「どの段階でどんな行動を強化するかを設計すること」にあります。
つまり、単に優しく接するのではなく、
「どのステップを通れば自然に理想行動にたどり着けるか」を考える“行動設計”の考え方です。
例えば、勉強が苦手な子の場合:
| ステップ | 行動 | 強化(報酬)例 |
|---|---|---|
| ① | 勉強道具を机に出した | 「よし、準備できたね!」と声をかける |
| ② | 1ページだけ開いた | 「少しでもやれたね!」と認める |
| ③ | 10分集中して取り組んだ | 「すごい!続けてできたね」と強化 |
| ④ | 自主的に勉強を始めた | 「自分でできたね!」と賞賛する |
このように、行動を細かく区切って強化するプロセスがシェイピングです。
まとめ
- シェイピングとは、段階的に理想行動を形成する心理学的手法。
- 行動心理学者スキナーの実験から生まれた「強化」の考え方を応用した手法である。
- 単なる「褒める」ではなく、「どの段階をどんなタイミングで強化するか」を設計することが本質。
シェイピング法とは?行動形成との違い
シェイピング法(シェイピング)とは、理想の行動を一気に身につけさせるのではなく、少しずつ段階的に近づけていく方法のことです。
心理学では「行動形成(Behavior Shaping)」とも呼ばれ、ほぼ同じ意味で使われます。
ただし、厳密にはニュアンスに少し違いがあります。
シェイピングと行動形成の違い
- シェイピング
→ 行動を段階的に強化していく「具体的な方法・技法」 - 行動形成
→ 行動が変化・定着していく「プロセス全体」
イメージで理解すると
- 行動形成=ゴールまでの「変化の流れ」
- シェイピング=その流れを作るための「やり方」
なぜ同じ意味で使われるのか
実際の現場では、
- シェイピング=行動形成
- 行動形成=シェイピング
のように、ほぼ同義語として扱われることが多いです。
そのため、
「シェイピング法とは?」
「行動形成とは?」
どちらも同じ内容を説明している記事が多いのが特徴です。
混乱しやすいですが、覚えるべきポイントはシンプルです。
シェイピングも行動形成も、どちらも「行動を少しずつ変えていく仕組み」を指します。
シェイピングの仕組みと理論背景|行動を変える3つのステップ
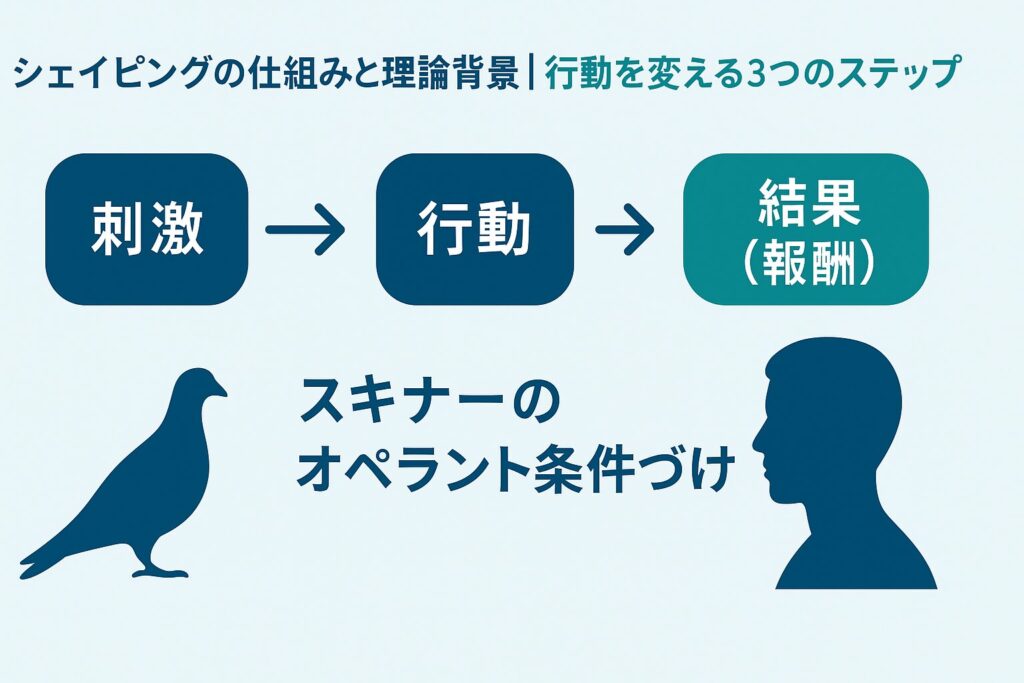
スキナーの「オペラント条件づけ」とは?シェイピングとの関係
シェイピングを理解するには、まず「オペラント条件づけ」という理論を押さえておく必要があります。
これは、行動はその結果によって増えたり減ったりするという学習の仕組みです。
心理学者のB.F.スキナーが提唱しました。
たとえば、ラットの実験では――
- 偶然レバーをつつく
- その直後にエサが出る
- 「この行動をすると良いことが起こる」と学習し、繰り返すようになる
このように、良い結果が続く行動は増えていくのが特徴です。
スキナーはこの原理を応用し、ハトがボールをつつくなどの複雑な行動を段階的に学ぶ様子を観察しました。
これがまさにシェイピング(行動形成)の考え方の始まりです。
つまり、人も動物も「結果によって行動を学ぶ」という仕組みで動いています。
そして、その仕組みを使って、少しずつ目標行動に近づけていく方法がシェイピングです。

逐次接近法(Successive Approximation)のプロセス
シェイピングでは、いきなり目標行動を求めるのではなく、
目標に「少し近い行動」から順番に強化していくという手順をとります。
これを「逐次接近法」といいます。
実際の手順は次のようになります。
シェイピングの3ステップ
- 初期行動を見つける
目標に向けて「最初の小さな一歩」を決める。
(例:運動習慣をつけたい→まずは服を着替える) - 段階的に強化していく
できた行動をその都度、褒める・報酬を与える。
(例:着替えた→外に出た→10分歩いた、の順で強化) - 最終的な行動に近づける
途中の行動では報酬を与えず、最終目標の行動だけを強化して定着させる。
このように、一歩ずつ「できた」を積み重ねる設計が、シェイピングの肝です。
強化の種類(正の強化・負の強化)と使い分け
シェイピングで使う「強化」には、2つのタイプがあります。
| 種類 | 意味 | 具体例 |
|---|---|---|
| 正の強化 | 行動の後に「うれしい結果」を与えて、行動を増やす | ほめる、報酬を与える、承認する |
| 負の強化 | 行動の後に「嫌な刺激を取り除いて」、行動を増やす | 嫌な課題がなくなる、ストレスが減る |
たとえば、
- 「部屋を片づけたらお菓子をもらえた」→正の強化
- 「宿題を終えたらテレビを見てもいい」→負の強化
どちらも「行動を増やす」ことが目的であり、罰とは異なります。
つまり、叱ることではなく、「行動を継続させる仕組み」を作るのがシェイピングです。
シェイピングの基本原則
シェイピングでは基本的に「罰(punishment)」は使いません。
これはシェイピングの重要な特徴の一つです。
シェイピング(行動形成)は、「望ましい行動を増やす」ための学習法です。
したがって、使うのは罰でなはく、「強化(Reinforcement)」です。
つまり――
- 正の強化(うれしい結果を与えて行動を増やす)
- 負の強化(嫌な刺激を取り除いて行動を増やす)
この2つだけが基本ツール。
目的は常に「行動を増やすこと」であり、「罰を与えて減らす」ことではありません。
ではなぜ「罰」を使わないのか?
心理学的に、罰には次のような副作用があるからです。
| 問題点 | 内容 |
|---|---|
| 恐怖や不安が学習される | 行動ではなく「罰を避けること」を覚えてしまう |
| 指導者への反感や回避行動 | 関係性が悪化し、隠す・嘘をつくなどの行動が出やすい |
| 「何をすればよいか」が学べない | 不適切な行動をやめても、望ましい行動が育たない |
一方、シェイピングは「正しい行動を育てる」方法なので、
“できた瞬間を強化する”ことに集中します。
ただし、現実の指導では「消去」や「軽い抑止」が使われる場合も
完全に無視できない行動(例:危険行動、暴力、迷惑行為など)の場合は、
「罰」というよりも、“強化しない(=消去)”や“行動を止める一時的な抑止”が使われます。
つまり、
- 「罰を使ってやめさせる」のではなく、
- 「報酬を与えないことで自然に減らす」
というのがシェイピング的アプローチです。
まとめ
- シェイピングは罰ではなく強化で行動を育てる。
- 強化は「行動を増やす」目的、罰は「行動を減らす」目的。
- 罰は短期的に効果があっても、副作用が大きく持続しにくい。
- 現実では「罰」よりも、「強化を与えない」「安全に止める」が実践的。
成功率を高める「強化スケジュール」の考え方
シェイピングでは、報酬(強化)のタイミングがとても重要です。
スキナーは実験の中で、「どのタイミングで報酬を与えると行動が安定するか」を研究しました。
代表的な4つのパターンを見てみましょう。
| タイプ | 内容 | 効果の特徴 |
|---|---|---|
| 連続強化 | 行動のたびに報酬を与える | 初期学習に効果的。早く覚えるが、やめやすい。 |
| 固定間隔強化 | 一定の時間ごとに報酬を与える | 規則的に行動が増える(例:給料日) |
| 変動間隔強化 | ランダムな時間で報酬を与える | 継続性が高い(例:SNSの「いいね」) |
| 変動比率強化 | 行動回数がランダムで報酬を与える | 最も強固な行動維持効果(例:ガチャ、ギャンブル) |
特に最後の「変動比率強化」は、行動を最も強く維持します。
私たちがSNSやスマホゲームに夢中になるのも、この仕組みが働いているからです。
つまり、「報酬の設計次第で、行動の定着率が変わる」――これがシェイピングの科学的な核心です。

まとめ
- シェイピングは、スキナーのオペラント条件づけ理論に基づく行動形成法。
- 目標に少しずつ近づける「逐次接近法」で行動を育てる。
- 正の強化・負の強化を適切に使い分けることで、行動の継続を促せる。
- 強化のタイミング(スケジュール)を工夫することで、行動は習慣化しやすくなる。
習慣化・モチベーション維持に効くシェイピングの活用法
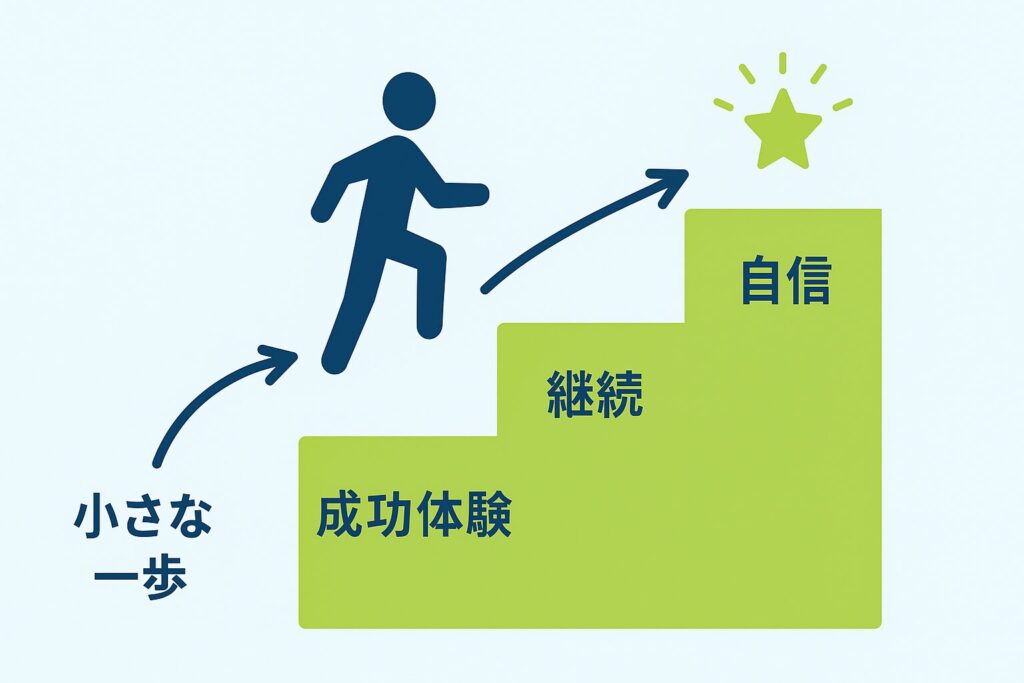
「小さな一歩」を積み重ねる行動設計のコツ
行動を変えたいのに続かない――。
多くの人が挫折する理由は、「最初から完璧を目指す」からです。
シェイピングでは、いきなり大きな行動を求めず、「できる範囲の小さな一歩」から始めます。
たとえば、「毎日1時間勉強する」はハードルが高いですが、
「1分だけ机に向かう」「ノートを開く」といった最初の行動なら、誰でもできます。
このように、行動のハードルを極限まで下げることで、「できた」という成功体験が増え、脳が「この行動は良いこと」と認識します。
これが行動を継続させる心理的トリガーです。
- スモールステップを設定する(最初は「形だけ」でOK)
- 行動後には小さな報酬(ほっと一息・チェックマークなど)を入れる
- 「やる気」より「習慣」を優先する
シェイピングは「頑張るための心理学」ではなく、
“続けられる仕組みを作る心理学”です。
自己強化(セルフシェイピング)で自分を育てる
シェイピングは他人に使うだけでなく、自分自身にも応用できます。
これを「自己強化(セルフシェイピング)」といいます。
自己強化の流れは以下の通りです。
- 目標行動を決める(例:毎朝10分運動する)
- 段階を決める(最初は「ストレッチだけ」でOK)
- 行動できたら、自分で自分を褒める・報酬を与える
- 次のステップに進む(少しずつ負荷を上げる)
ここで重要なのは、「サボっても自分を責めない」こと。
シェイピングの考え方では、失敗も含めて“学習の過程”です。
自分を否定せず、できたことに注目することで自己効力感(自分はできるという感覚)が高まり、行動が安定します。

行動を続けるための報酬設計|外発的から内発的へ
多くの人が「やる気が続かない」と感じるのは、外的報酬(ご褒美)に頼りすぎているからです。
最初はそれでも構いませんが、シェイピングでは徐々に報酬を「内側の満足」に移行させることが大切です。
| 段階 | 報酬の種類 | 例 |
|---|---|---|
| 初期 | 外発的報酬(外からの刺激) | ご褒美・ほめ言葉・SNSでの承認 |
| 中期 | 達成感の報酬 | 「昨日よりできた」「続いてる自分すごい」 |
| 最終 | 内発的報酬(内側の動機) | 「やること自体が楽しい」状態 |
この流れを意識して行動を設計すると、
“やらされ感”から“自然にやりたくなる状態”へと変化していきます。
心理学ではこれを内発的動機づけの内在化と呼びます。
シェイピングは、そのプロセスを実生活レベルで実現できる方法なのです。
もともと興味がある活動に報酬を付与してしまうと、「自分がその活動をやるのは報酬のためだ」と認識されてしまい、内発的動機が弱まることがあります。これは「アンダーマイニング効果」と呼ばれる現象です。

習慣化がうまくいく人の思考パターン
習慣化が成功する人と失敗する人の違いは、「行動の捉え方」にあります。
| 思考の違い | 失敗しやすい人 | うまくいく人 |
|---|---|---|
| 行動の基準 | 結果を求めすぎる | プロセスを評価する |
| 自己評価 | できなかったことに注目 | できたことを認める |
| 継続のコツ | 「やらなきゃ」思考 | 「少しでもやってみよう」思考 |
つまり、「完璧にやる」よりも「できたことを積み上げる」人のほうが続くのです。
シェイピング思考とは、まさにこの“積み上げ型の心理”を科学的に支える方法です。
まとめ
- シェイピングは「やる気」に頼らず、「できた」を積み重ねる習慣化の心理学。
- 自分を責めるのではなく、できた部分に注目して自己強化することがカギ。
- 報酬は外的から内的へ移行させると、自然にモチベーションが続く。
- 習慣化の本質は、「行動を継続できる設計」にある。
シェイピングを成功させるポイントと注意点
強化のタイミングを逃さないコツ
シェイピングで最も重要なのは、強化(報酬や承認)のタイミングです。
なぜなら、行動直後の反応こそが、脳に「これが正しい行動だ」と学習させるからです。
心理学の研究では、行動と報酬の間隔は短いほど良い(数秒以内が理想)と言われています。
それ以上時間が空くと、どの行動が原因なのか分からなくなり、学習効果が下がってしまいます。
たとえば、子どもが宿題を始めた瞬間に「いいね!」と声をかけるのは◎。
終わって30分後に褒めても、「何が良かったのか」が結びつきません。
- 行動直後に強化する(即時性が命)
- 言葉・笑顔・うなずきなど、非言語でもOK
- 「できた」瞬間を逃さず反応する
タイミングの一瞬を逃さないことが、シェイピングの成否を分けるのです。
ステップを飛ばすと失敗する理由
シェイピングの原則は「段階を一つずつ積み上げる」こと。
しかし、ここを焦ってステップを飛ばすと、行動が定着せずに挫折してしまいます。
例えば、運動が苦手な人にいきなり「毎日10km走ろう」と言っても続かないのは当然。
それよりも、
- まずは1分歩く
- 次に5分
- 週に1回でもOK
このように「成功できるハードル」を少しずつ上げることが大切です。
ステップを飛ばすと、報酬と達成感の間にギャップが生まれ、モチベーションが崩れるのです。
失敗しやすいパターン
- 最初から高すぎる目標設定
- “できなかった”日が続く
- 自信喪失 → 行動停止
成功の秘訣は、「常に成功体験を積み上げる設計」にすることです。
継続のカギは「成功体験の積み重ね」
シェイピングの効果を最大限に発揮するには、小さな成功体験を繰り返すことです。
人は「できた」という体験を積むたびに、脳内でドーパミンが分泌され、快感と学習が結びつきます。
つまり、「できた=うれしい」という感情が、次の行動を自動的に引き出してくれるのです。
たとえば、
- タスクを終えたらチェックマークを入れる
- 運動後に鏡を見て達成感を味わう
- SNSで進捗を共有して承認を得る
このように、自分で“報酬の仕組み”をデザインすることが、継続のポイントです。
心理学的には、この流れを「強化の連鎖」と呼びます。
一度この連鎖ができると、努力せずとも行動が自動化していくのです。
まとめ
- タイミングは即時性が命。 行動直後の強化が最も効果的。
- ステップを飛ばすと失敗。 小さな成功を積み重ねることが継続のカギ。
- 成功体験が行動を自動化する。報酬を設計して快感と結びつける。
シェイピング法の具体例|行動形成の活用法(日常・教育・ビジネス)

日常生活での応用例|ダイエット・勉強・運動習慣
シェイピングの考え方は、日常生活のあらゆる「続かないこと」に応用できます。
たとえば、ダイエット・運動・勉強・早起きなど、やる気はあっても続かない習慣です。
ここで大切なのは、完璧を目指さないこと。
シェイピングでは「一気に変える」のではなく、「できたことを少しずつ増やす」ことに焦点を当てます。
たとえばダイエットなら――
| ステップ | 行動 | 強化(報酬)例 |
|---|---|---|
| ① | お菓子を減らす | 1日我慢できたらお気に入りの紅茶を飲む |
| ② | 野菜を1品増やす | 自分を褒める/記録アプリで達成マークをつける |
| ③ | 毎日10分ウォーキング | 1週間続いたら好きな音楽を買う |
| ④ | 週3回ジムに通う | SNSで成果を共有して承認を得る |
このように、「行動→小さな達成感→次の行動」という流れを作ることで、
無理なく習慣化できるのです。
教育現場での活用|子どものやる気を引き出すステップ指導
子どもの指導では、つい「できていない部分」に目が行きがちです。
しかしシェイピングの視点では、「できた部分を強化して伸ばす」ことが基本です。
たとえば、子どもに「宿題を全部やりなさい」と叱るよりも、
- ノートを開いた
- 1問だけ解いた
- 最後までやり切った
という小さなステップごとに認めるほうが、行動は定着します。
職場でのマネジメント活用|小さな成果を認めて行動を育てる
ビジネスの現場でも、シェイピングの原理は非常に役立ちます。
特に、部下育成や新人教育においては、「結果」よりも「プロセス」を強化することが効果的です。
例を挙げると、
- いきなり成果を求めず、行動の段階ごとに認める
- 「できた報告」を受けたら即フィードバックする
- 徐々に目標を上げ、自発的な行動を促す
このように、行動を「できた」「できない」で判断するのではなく、
「どれくらい目標に近づいたか」を見て強化することがポイントです。
ペットトレーニングに見るシェイピングの実例
シェイピングは、動物のトレーニングにも使われています。
たとえば犬に「お座り」を教える場合――
- 座りそうな動きをした瞬間に「よし!」と声をかけておやつを与える
- 何度か繰り返すうちに、犬が「座る=いいことが起こる」と学習する
- 最終的に、「お座り」と言葉を聞くだけで行動が安定する
これは、スキナーがハトで行った実験と同じ構造です。
つまり、動物も人間も、行動は「強化」によって形成されるということです。
まとめ
- シェイピングは日常生活、教育、ビジネスなどあらゆる場面に応用可能。
- 重要なのは、「理想行動」ではなく「今できたこと」に注目して強化すること。
- “どう行動を強化設計するか”が鍵。
ほめすぎの落とし穴|外的報酬に依存させないシェイピング設計
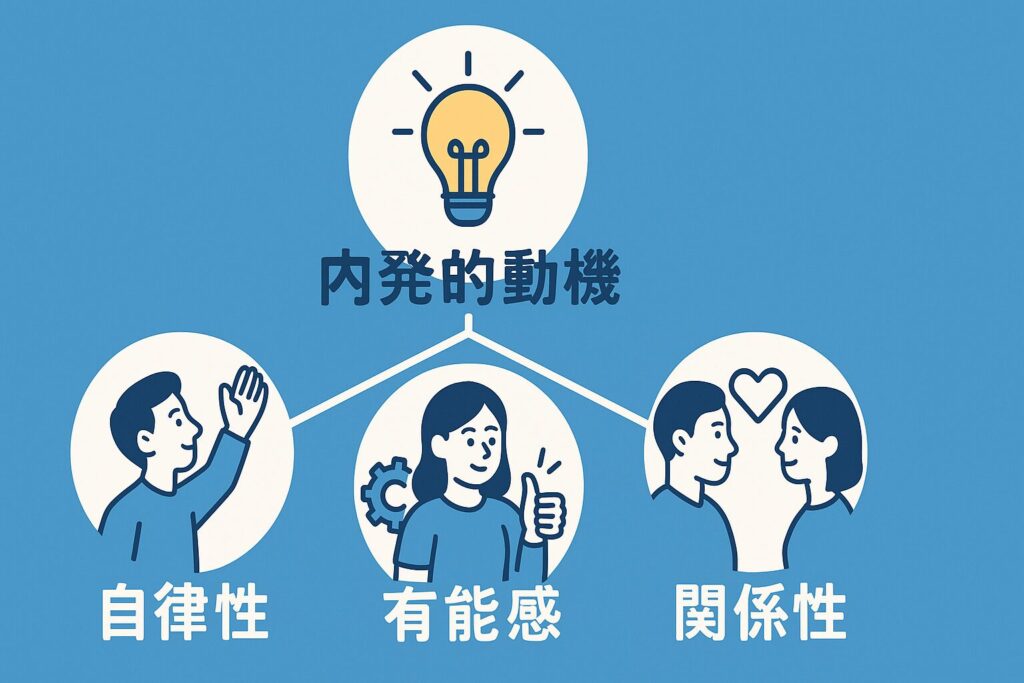
「ほめれば伸びる」と言われますが、ほめすぎは逆効果になることがあります。
理由は、人が「外的報酬(ほめられること)」に依存してしまうからです。
たとえば、
「ほめられないとやらない子」や「評価されないと動かない部下」が生まれるのは、
外発的動機づけに頼りすぎた結果です。
シェイピングの最終目的は、内発的動機づけ(自分の中のやる気)を育てることです。
ポイントは次の3つです。
① 自分で選べる余地を与える(自律性)
人は「やらされている」と感じると、モチベーションが下がります。
「どれからやる?」「どんなやり方がいいと思う?」と問いかけ、
自分で選んで動く機会を作ることで、やる気が長続きします。
② できたことを“自分の成長”として認識させる(有能感)
「えらいね」よりも、「前よりスムーズにできたね」「工夫したね」と、
行動の質や努力に焦点を当ててフィードバックすることで、
「自分は成長できている」という感覚(有能感)が強まります。
③ 誰かとのつながりを感じられる(関係性)
応援してくれる人や、認め合える関係があると、
行動の意味が深まり、自然とモチベーションが続きます。
シェイピングは「人との関係を通して成長を支援する仕組み」とも言えます。

シェイピングと他の心理学的アプローチとの違い
行動連鎖(チェイニング)との違い|複数行動を組み立てる手法
シェイピングとよく混同されるのが、チェイニング(Chaining:行動連鎖)です。
どちらも「行動を形成する」心理学的手法ですが、目的が少し異なります。
| 手法 | 目的 | 具体例 |
|---|---|---|
| シェイピング | 1つの行動を少しずつ理想形に近づける | 「正しい発音を段階的に習得する」 |
| チェイニング | 複数の行動をつなげて1つの流れを作る | 「歯を磨く」=歯ブラシを取る→歯磨き粉をつける→磨く→口をゆすぐ |
つまり、
- シェイピング:“行動の質”を少しずつ変える
- チェイニング:“行動の順序”を組み立てる
という違いです。
例えば、ダンスの練習で「1つのステップを正確にできるようにする」のがシェイピング。
「複数のステップをつなげて1曲通して踊る」のがチェイニングです。
両者を組み合わせることで、より複雑な行動学習(スポーツ・職業訓練・リハビリなど)が可能になります。
モデリング(観察学習)との違い|見て学ぶ vs 強化で学ぶ
もう一つ混同されやすいのが、モデリング(Modeling)=観察学習です。
これは、心理学者アルバート・バンデューラ(Albert Bandura)が提唱した理論で、
「人は他人の行動を観察することで学ぶ」という考え方に基づきます。
たとえば、
- 子どもが親の真似をして「ありがとう」と言うようになる
- 新入社員が先輩のプレゼンを見て、自分も同じように話す
このように、モデリングでは他人の成功体験が刺激になるのです。
一方、シェイピングは観察ではなく、自分の行動と結果の積み重ねによって学びます。
| 比較項目 | シェイピング | モデリング |
|---|---|---|
| 学習の方法 | 結果による学習(強化) | 他者の観察による学習 |
| 主体 | 自分の行動 | 他人の行動 |
| 使われる場面 | 習慣化・トレーニング | 教育・対人スキル・社会的学習 |
このように、どちらも学習を支援する方法ですが、
シェイピングは「行動を設計する心理学」、
モデリングは「行動を模倣する心理学」です。

行動療法・認知行動療法との関係
シェイピングは、行動療法(Behavior Therapy)の一種として位置づけられます。
行動療法は「人の行動は学習によって変えられる」という考え方に基づき、
恐怖症や不安障害、依存などの治療にも応用されています。
さらに、思考の歪みや感情のクセも扱うようになったのが、認知行動療法(CBT)です。
- 行動療法:外側の「行動」を変える
- 認知行動療法:内側の「考え方(認知)」も変える
たとえば、
「運動が続かない人」に対して――
- 行動療法的アプローチ → 小さなステップで実行させる(シェイピング)
- 認知行動療法的アプローチ → 「できない自分はダメ」という考えを修正する
というように、シェイピングは“行動面のアプローチ”に特化した実践的技法といえます。

現代AIにも応用される「報酬設計(Reward Shaping)」との類似点
実はこの「シェイピング」という考え方、現代のAI(人工知能)学習にも使われています。
AIの分野では「報酬設計(Reward Shaping)」と呼ばれ、
AIが目標に向けて学習する際に、「段階的に報酬を与える仕組み」が取り入れられています。
たとえば、ロボットがドアを開けるタスクを学習する場合――
- ① ドアに近づく → 小さな報酬
- ② ドアノブをつかむ → 中くらいの報酬
- ③ ドアを開ける → 大きな報酬
こうした段階的な強化設計によって、AIが効率的に学習できるようになるのです。
つまり、現代のテクノロジーにも、スキナーのシェイピング理論が応用されているということです。
まとめ
- シェイピングは「行動の質を少しずつ変える」心理学的手法。
- チェイニング(行動連鎖)は「複数行動の順序を組み立てる」手法。
- モデリングは「他者の行動を観察して学ぶ」手法。
- 認知行動療法の中では、シェイピングは実践的な行動変容の技法として使われる。
- 現代のAIにも応用されるなど、普遍的な行動設計理論である。
まとめ|シェイピングを理解すれば行動は確実に変えられる
行動は「一度に変えようとしない」ほうがうまくいく
人は「明日から完璧に変わろう」と思いがちですが、心理学的にはそれが最も挫折しやすいパターンです。
なぜなら、脳は「急激な変化」をストレスとして捉え、現状維持を優先するからです。
シェイピングの原則は、「少しずつ」「できたところから」変えること。
つまり、変化を“設計”していくことで、脳に無理なく行動を覚え込ませることができます。
一気に変えるより、段階的に変えるほうが長続きする理由
- 脳の抵抗を減らせる(負担が小さい)
- 「できた!」という快感を積み重ねられる
- 自信が自然に育ち、行動が自動化していく
行動変容は意志ではなく仕組みで起こすもの。
これがシェイピングの最大の学びです。
シェイピングは“行動を設計する”心理学
シェイピングの本質、「行動をどう設計するか」という発想です。
人は結果ではなく、「結果までの過程」を強化されることで変わります。
だからこそ、
- 行動のどの段階を評価するか
- どんな報酬やフィードバックを与えるか
をデザインすることが重要なのです。
つまり、シェイピングとは――
「自分や相手の行動を観察しながら、少しずつ理想に導く心理学的設計図」
これは教育・人材育成・自己成長など、あらゆる分野に通じる基本原理です。
習慣化・教育・マネジメントに応用できる普遍的な理論
シェイピングは、子どものしつけから企業の人材育成、さらにはAI学習まで応用されています。
この理論が時代を超えて使われるのは、「行動の変化には段階がある」という普遍的な原理を示しているからです。
応用の一例を挙げると:
| 分野 | 活用例 | ポイント |
|---|---|---|
| 教育 | 小さな成功体験を積ませる指導 | 「叱る」より「行動を設計」する |
| ビジネス | 部下の成長プロセスを段階的に評価 | 結果より「変化の軌跡」を見守る |
| 習慣化 | 自己強化で続けられる仕組みを作る | 外的報酬から内的動機づけへ |
このように、シェイピングは単なる心理実験の理論ではなく、
「人を育てる・自分を変える」ための実用的な思考法です。
まとめ:行動は“意志”ではなく“設計”で変わる
- シェイピングとは、段階的に行動を形成する心理学的手法。
- 一気に変えるのではなく、「小さな成功」を積み上げて変化を作る。
- 強化(報酬・承認)のタイミングを設計することで、行動は自然に定着する。
- 「どの行動を強化するか」を考えることが大切。
- 習慣化・教育・マネジメントなど、あらゆる分野に応用できる。